
- 分类: 网络辅助
- 星级:
- 语言: 简体中文
- 版本: v2022.04.20 中文最新版
- 更新: 2024-09-16
- 大小: 4.6M
游戏简介
纯真QQ IP数据库是纯真专为QQ制作的IP地址数据库,包括全国多家运营商的IP地址数据,电信、网通、长城宽带ip地址应有尽有,每周都会更新版本,有需要的就来下载吧!
纯真ip地址数据库介绍
IP数据记录:529210条
数据库大小:9M
收集了包括中国电信、中国移动、中国联通、长城宽带、聚友宽带等 ISP 的 IP 地址数据,包括网吧数据。
希望能够通过大家的共同努力打造一个没有未知数据,没有错误数据的QQ IP。IP数据库每7天更新一次,请大家
定期更新IP数据库!
因为IP地址数据是民间收集的,各运营商也会不时的更改IP段,所以有点遗漏、错误是难免的。随数据库附
送IP解压,查询软件。假如发现IP地址有不对的,或想提供新的IP地址,请到网站https://www.cz88.net提供IP地址数据,
或者发送电子邮件到admin@cz88.net告诉我们。以便及时更新IP数据库。谢谢!
在线升级数据库
随数据库附送的查询程序(IP.EXE)具有在线检测并升级IP数据库的功能,只要运行该程序,点击右上角的“在线升级”,就可以升级IP数据库到最新的版本,无需再到下载网站下载新版的IP数据库。
纯真IP数据库格式详解
纯真版IP数据库,优点是记录多,查询速度快,它只用一个文件QQWry.dat就包含了所有记录,方便嵌入到其他程序中,也方便升级。缺点是你想要编辑它却是比较麻烦的,由于其文件格式的限制,你要直接添加IP记录就不容易了
基本结构
QQWry.dat 文件在结构上分为3块:文件头,记录区,索引区。一般我们要查找IP时,先在索引区查找记录偏移,然后再到记录区读出信息。由于记录区的记录是不定长的, 所以直接在记录区中搜索是不可能的。由于记录数比较多,如果我们遍历索引区也会是有点慢的,一般来说,我们可以用二分查找法搜索索引区,其速度比遍历索引 区快若干数量级。图1是QQWry.dat的文件结构图。
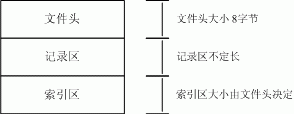
图1. QQWry.dat文件结构
要注意的是,QQWry.dat里面全部采用了little-endian字节序
一. 了解文件头
QQWry.dat的文件头只有8个字节,其结构非常简单,首四个字节是第一条索引的绝对偏移,后四个字节是最后一条索引的绝对偏移。
二. 了解记录区
每 条IP记录都由国家和地区名组成,国家地区在这里并不是太确切,因为可能会查出来“清华大学计算机系”之类的,这里清华大学就成了国家名了,所以这个国家 地区名和IP数据库制作的时候有关系。所以记录的格式有点像QName,有一个全局部分和局部部分组成,我们这里还是沿用国家名和地区名的说法。
于 是我们想象着一条记录的格式应该是: [IP地址][国家名][地区名],当然,这个没有什么问题,但是这只是最简单的情况。很显然,国家名和地区名可能会有很多的重复,如果每条记录都保存一 个完整的名称拷贝是非常不理想的,所以我们就需要重定向以节省空间。所以为了得到一个国家名或者地区名,我们就有了两个可能:第一就是直接的字符串表示的 国家名,第二就是一个4字节的结构,第一个字节表明了重定向的模式,后面3个字节是国家名或者地区名的实际偏移位置。对于国家名来说,情况还可能更复杂 些,因为这样的重定向最多可能有两次。
那么什么是重定向模式?根据上面所说,一条记录的格式是[IP地址][国家记录][地区记录],如果国家记录是重定向的话,那么地区记录是有可能没有的,于是就有了两种情况,我管他叫做模式1和模式2。我们对这些格式的情况举图说明:

图2. IP记录的最简单形式
图2表示了最简单的IP记录格式,我想没有什么可以解释的
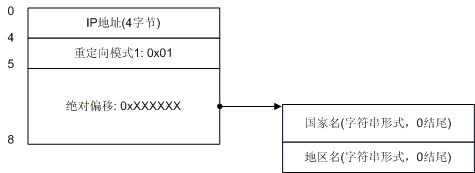
图3. 重定向模式1
图3演示了重定向模式1的情况。我们看到在模式1的情况下,地区记录也跟着国家记录走了,在IP地址之后只剩下了国家记录的4字节,后面3个字节构成了一个指针,指向了实际的国家名,然后又跟着地址名。模式1的标识字节是0x01。
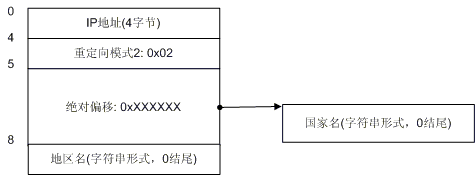
图4. 重定向模式2
图 4演示了重定向模式2的情况。我们看到了在模式2的情况下(其标识字节是0x02),地区记录没有跟着国家记录走,因此在国家记录之后4个字节之后还是有 地区记录。我想你已经明白了模式1和模式2的区别,即:模式1的国家记录后面不会再有地区记录,模式2的国家记录后会有地区记录。下面我们来看一下更复杂 的情况。
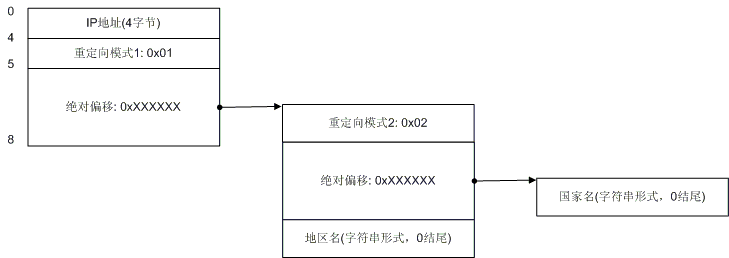
图5. 混和情况1
图 5演示了当国家记录为模式1的时候可能出现的更复杂情况,在这种情况下,重定向指向的位置仍然是个重定向,不过第二次重定向为模式2。大家不用担心,没有 模式3了,这个重定向也最多只有两次,并且如果发生了第二次重定向,则其一定为模式2,而且这种情况只会发生在国家记录上,对于地区记录,模式1和模式2 是一样的,地区记录也不会发生2次重定向。不过,这个图还可以更复杂,如图7:
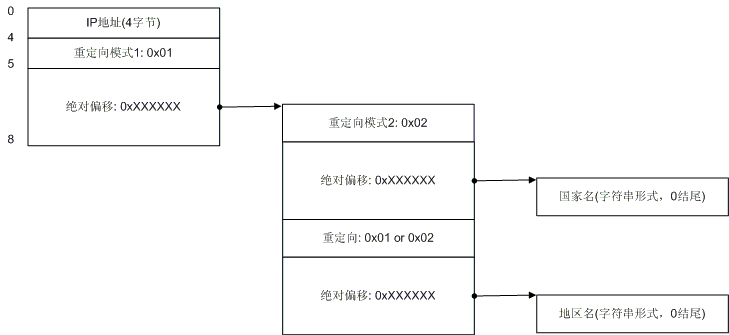
图6. 混和情况2
图6是模式1下最复杂的混和情况,不过我想应该也很好理解,只不过地区记录也来重定向而已,有一点我要提醒你,如果重定向的地址是0,则表示未知的地区名。
所 以我们总结如下:一条IP记录由[IP地址][国家记录][地区记录]组成,对于国家记录,可以有三种表示方式:字符串形式,重定向模式1和重定向模式 2。对于地区记录,可以有两种表示方式:字符串形式和重定向,另外有一条规则:重定向模式1的国家记录后不能跟地区记录。按照这个总结,在这些方式中合理 组合,就构成了IP记录的所有可能情况。
设计的理由
在我们继续去了解索引区的结构之前,我们先来了解一下为何记录区的结构要如此设 计。我想你可能想到了答案:字符串重用。没错,在这种结构下,对于一个国家名和地区名,我只需要保存其一次就可以了。我们举例说明,为了表示方便,我们用 小写字母代表IP记录,C表示国家名,A表示地区名:
有两条记录a(C1, A1), b(C2, A2),如果C1 = C2, A1 = A2,那么我们就可以使用图3显示的结构来实现重用
有三条记录a(C1, A1), b(C2, A2), c(C3, A3),如果C1 = C2, A2 = A3,现在我们想存储记录b,那么我们可以用图6的结构来实现重用
有两条记录a(C1, A1), b(C2, A2),如果C1 = C2,现在我们想存储记录b,那么我们可以采用模式2表示C2,用字符串表示A2
你可以举出更多的情况,你也会发现在这种结构下,不同的字符串只需要存储一次。
了解索引区
在"了解文件头"部分,我们说明了文件头实际上是两个指针,分别指向了第一条索引和最后一条索引的绝对偏移。如图8所示:
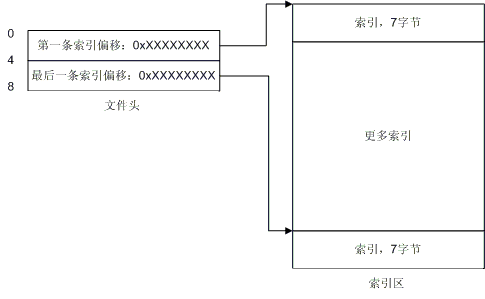
图8. 文件头指向索引区图示
实 在是很简单,不是吗?从文件头你就可以定位到索引区,然后你就可以开始搜索IP了!每条索引长度为7个字节,前4个字节是起始IP地址,后三个字节就指向 了IP记录。这里有些概念需要说明一下,什么是起始IP,那么有没有结束IP? 假设有这么一条记录:166.111.0.0 - 166.111.255.255,那么166.111.0.0就是起始IP,166.111.255.255就是结束IP,结束IP就是IP记录中的那头 4个字节,这下你应该就清楚了吧。于是乎,每条索引配合一条记录,构成了一个IP范围,如果你要查找166.111.138.138所在的位置,你就会发 现166.111.138.138落在了166.111.0.0 - 166.111.255.255 这个范围内,那么你就可以顺着这条索引去读取国家和地区名了。那么我们给出一个最详细的图解吧:
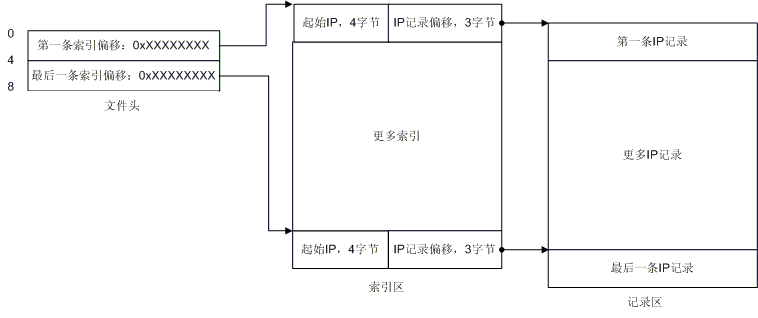
图9. 文件详细结构
现 在一切都清楚了是不是?也许还有一点你不清楚,QQWry.dat的版本信息存在哪里呢? 答案是:最后一条IP记录实际上就是版本信息,最后一条记录显示出来就是这样:255.255.255.0 255.255.255.255 纯真网络 2004年6月25日IP数据。OK,到现在你应该全部清楚了。
纯真QQ IP数据库使用方法
把文件QQWry.Dat解压到QQ的目录,覆盖原有的文件。
关闭QQ,重新启动。就能升级QQ的IP数据库。
假如qq目录里面有ip.dat,则删除该文件,把解压出来的QQWry.Dat改名为ip.dat。(赛博版QQ)
假如qq目录里面有CoralWry.dat,则删除该文件,把解压出来的QQWry.Dat改名为CoralWry.dat。(珊瑚虫版QQ)
假如qq目录里面有CaiHong.dat,则删除该文件,把解压出来的QQWry.Dat改名为CaiHong.dat。(彩虹版QQ)

















